How to create a repository on the Hub? How to configure it? How to interact with it?
How do I download a file from the Hub? How do I download a repository?
How to upload a file or a folder? How to make changes to an existing repository on the Hub?
How to efficiently search through the 200k+ public models, datasets and spaces?
How to interact with the Hub through a convenient interface that mimics Python's file interface?
How to make predictions using the accelerated Inference API?
How to interact with the Community tab (Discussions and Pull Requests)?
How to programmatically build collections?
How does the cache-system work? How to benefit from it?
How to create and share Model Cards?
How to manage your Space hardware and configuration?
What does it mean to integrate a library with the Hub? And how to do it?
How to create a server to receive Webhooks and deploy it as a Space?
`push_to_hub(model, ...)` | `model = MyModel.from_pretrained(...)`
`model.push_to_hub(...)` | | Flexibility | Very flexible.
You fully control the implementation. | Less flexible.
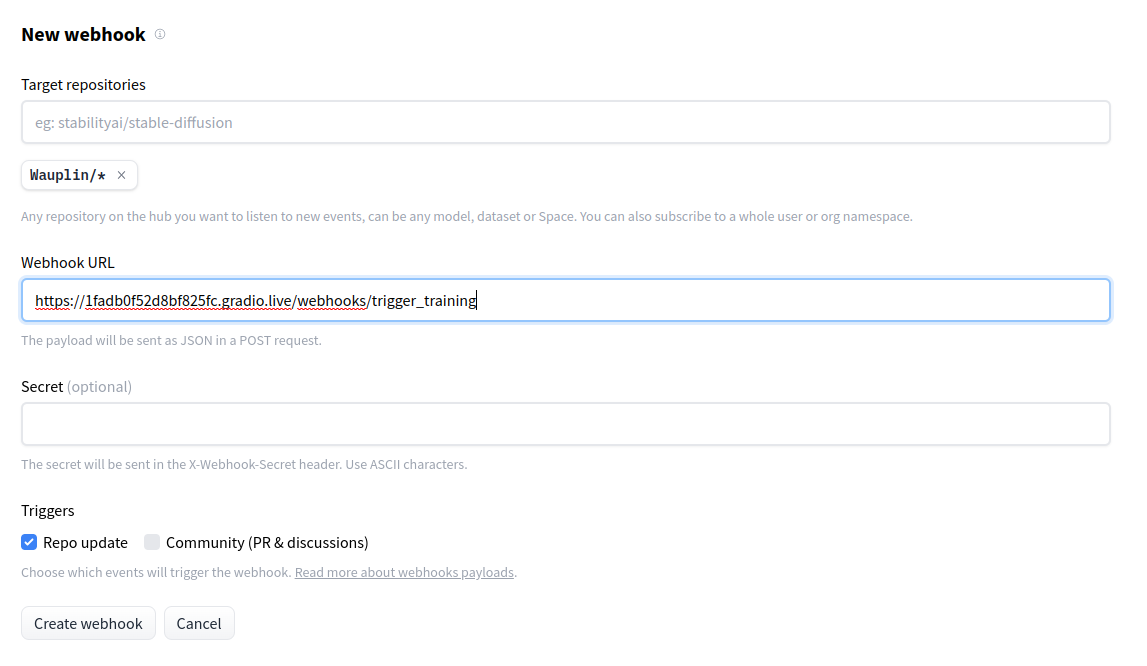
Your framework must have a model class. | | Maintenance | More maintenance to add support for configuration, and new features. Might also require fixing issues reported by users. | Less maintenance as most of the interactions with the Hub are implemented in `huggingface_hub`. | | Documentation / Type annotation | To be written manually. | Partially handled by `huggingface_hub`. | | Download counter | To be handled manually. | Enabled by default if class has a `config` attribute. | | Model card | To be handled manually | Generated by default with library_name, tags, etc. | # Webhooks Webhooks are a foundation for MLOps-related features. They allow you to listen for new changes on specific repos or to all repos belonging to particular users/organizations you're interested in following. This guide will first explain how to manage webhooks programmatically. Then we'll see how to leverage `huggingface_hub` to create a server listening to webhooks and deploy it to a Space. This guide assumes you are familiar with the concept of webhooks on the Huggingface Hub. To learn more about webhooks themselves, you should read this [guide](https://huggingface.co/docs/hub/webhooks) first. ## Managing Webhooks `huggingface_hub` allows you to manage your webhooks programmatically. You can list your existing webhooks, create new ones, and update, enable, disable or delete them. This section guides you through the procedures using the Hugging Face Hub's API functions. ### Creating a Webhook To create a new webhook, use `create_webhook()` and specify the URL where payloads should be sent, what events should be watched, and optionally set a domain and a secret for security. ```python from huggingface_hub import create_webhook # Example: Creating a webhook webhook = create_webhook( url="https://webhook.site/your-custom-url", watched=[{"type": "user", "name": "your-username"}, {"type": "org", "name": "your-org-name"}], domains=["repo", "discussion"], secret="your-secret" ) ``` ### Listing Webhooks To see all the webhooks you have configured, you can list them with `list_webhooks()`. This is useful to review their IDs, URLs, and statuses. ```python from huggingface_hub import list_webhooks # Example: Listing all webhooks webhooks = list_webhooks() for webhook in webhooks: print(webhook) ``` ### Updating a Webhook If you need to change the configuration of an existing webhook, such as the URL or the events it watches, you can update it using `update_webhook()`. ```python from huggingface_hub import update_webhook # Example: Updating a webhook updated_webhook = update_webhook( webhook_id="your-webhook-id", url="https://new.webhook.site/url", watched=[{"type": "user", "name": "new-username"}], domains=["repo"] ) ``` ### Enabling and Disabling Webhooks You might want to temporarily disable a webhook without deleting it. This can be done using `disable_webhook()`, and the webhook can be re-enabled later with `enable_webhook()`. ```python from huggingface_hub import enable_webhook, disable_webhook # Example: Enabling a webhook enabled_webhook = enable_webhook("your-webhook-id") print("Enabled:", enabled_webhook) # Example: Disabling a webhook disabled_webhook = disable_webhook("your-webhook-id") print("Disabled:", disabled_webhook) ``` ### Deleting a Webhook When a webhook is no longer needed, it can be permanently deleted using `delete_webhook()`. ```python from huggingface_hub import delete_webhook # Example: Deleting a webhook delete_webhook("your-webhook-id") ``` ## Webhooks Server The base class that we will use in this guides section is `WebhooksServer()`. It is a class for easily configuring a server that can receive webhooks from the Huggingface Hub. The server is based on a [Gradio](https://gradio.app/) app. It has a UI to display instructions for you or your users and an API to listen to webhooks.